DORA Metrics for AI Agent Teams
Most AI engineering teams measure model accuracy, eval scores, and cost per token. None of those measure delivery performance. The four DORA metrics translate one-to-one to AI agent teams once you redefine deployment - here is the operational framework, the per-metric translation, and how to instrument it this week.
An AI engineering team can ship a polished demo in a weekend and then take six weeks to push a single prompt change to production. The demo earns the team a budget. The six-week prompt change quietly costs them every quarter that follows. When leadership asks why the team feels slow, the dashboards point at model accuracy, eval scores, and cost per token. None of those numbers measures delivery performance, and delivery performance is what the team is actually being judged on.
DORA - the DevOps Research and Assessment program - gave traditional software teams a vocabulary for delivery performance fifteen years ago. The four key metrics (deployment frequency, lead time for change, change failure rate, and mean time to recovery) are the most rigorously validated measurement framework in our discipline. Teams that excel on the four are objectively faster, more reliable, and more profitable than teams that do not (Forsgren, Humble, and Kim, Accelerate, IT Revolution Press, 2018; DORA, State of DevOps Report 2024). AI agent teams are operating without that vocabulary today, which is why so many of them ship demos quickly and ship production updates slowly.
The translation we run on our own teams is not metaphorical. A prompt change, an eval set update, a new tool registration, a model version pin, a context window expansion, a permission scope change, a knowledge base update - these are deployments. They have failure rates. They have lead times. They have recovery times. Treat them that way and the four metrics measure what they were always meant to measure: how fast a team can change the system in production without breaking it.
The translation in one sentence
This post is the framework, the per-metric translation, and a starting practice for next week. It opens our DevOps and PeopleOps for AI Agent Teams series, and it is the operational measurement layer that the rest of the series assumes.
The four metrics, briefly
The four DORA key metrics measure two things: throughput (deployment frequency, lead time for change) and stability (change failure rate, mean time to recovery). The 2024 report introduced a fifth metric, reliability, which measures the team's ability to meet operational performance goals. The four-plus-one structure is not a coincidence. Throughput without stability is reckless; stability without throughput is stagnant; reliability is what the user experiences when both are healthy.
The gap between elite and low-performing teams is not a rounding error. Across years of State of DevOps reporting, elite teams ship hundreds of times more often than low performers and recover from incidents in orders-of-magnitude less time. Teams that excel on one of the four tend to excel on all four. The metrics are correlated because the underlying capabilities - continuous integration, trunk-based development, version control, observability, automated testing - reinforce each other.
An important property is that the four are outcomes, not practices. You do not directly improve deployment frequency; you improve the underlying capabilities that make frequent deployments safe, and the metric moves. The same is true for the AI agent translation. We are not asking you to ship more prompts for the sake of it. We are asking you to build the capability to ship prompts safely, and then to measure whether you are using it. The principle behind this is Hypothesis Experiment Measure Iterate applied to delivery itself.
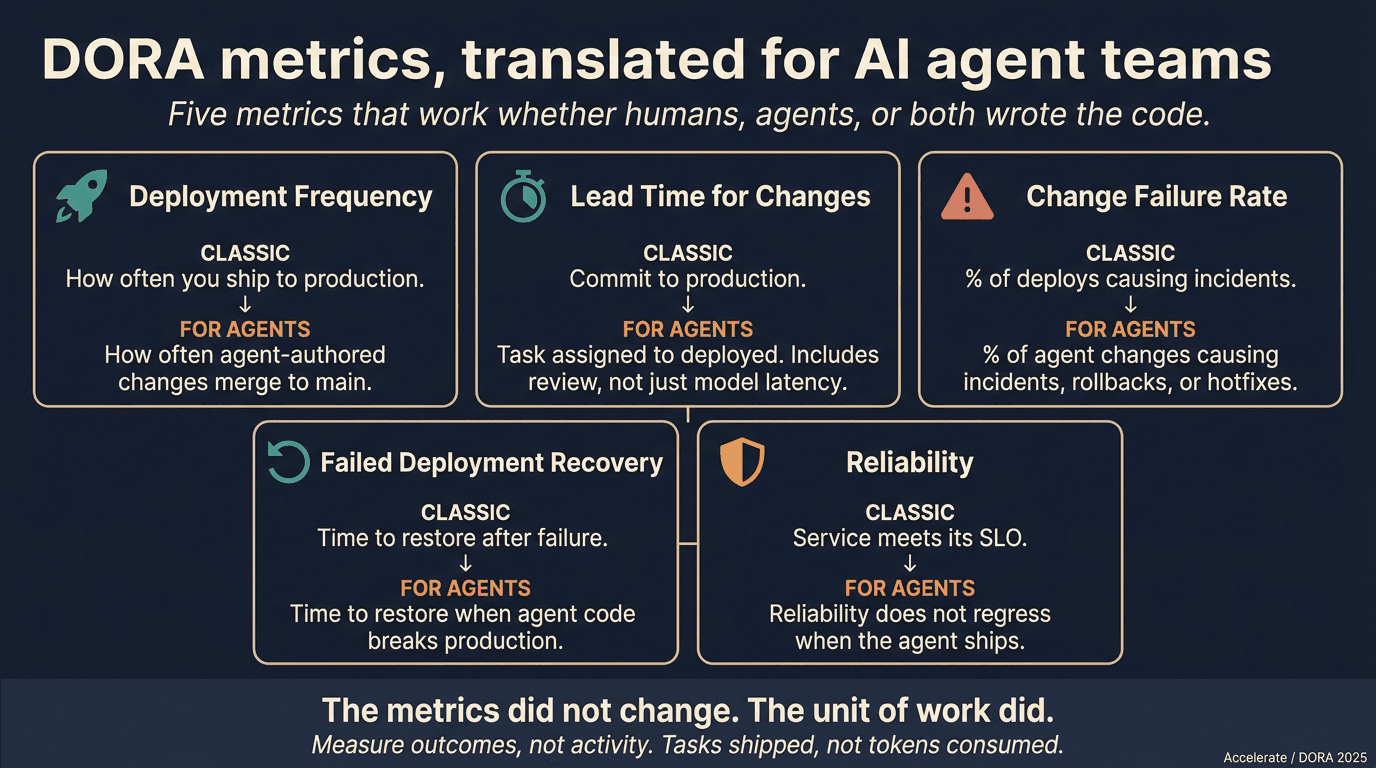
Deployment frequency for AI agent teams
The traditional definition is: how often the team ships a change to production that reaches users. The AI agent translation requires us to be precise about what "a change" is. In the systems we run, a deployment is any of the following.
What counts as a deployment
- System prompt or user prompt template change
- Few-shot example added, removed, or reordered
- Eval set update (new cases or threshold change)
- Tool registration, removal, or schema change
- Model version pin (for example,
gpt-4o-2024-08-06togpt-4o-2024-11-20) - Context window or memory configuration change
- Permission or guardrail scope change
- Knowledge base or Retrieval-Augmented Generation index update
Why the granularity matters
Small frequent changes are diagnosable; large infrequent changes are not. A team that ships one prompt edit and watches the eval suite has a bisectable history. A team that ships a quarterly "major prompt overhaul" has a regression they cannot trace. The same logic that drives daily software deployments - the kind we wrote about in why we deploy daily - applies to agent updates without modification.
The anti-pattern is the team that says, with some pride, that they shipped a major prompt revision last quarter. That is a low-frequency team by any DORA reading. The elite practice is the opposite: prompt and eval changes ship daily, behind canary cohorts or feature flags where the blast radius justifies it, with rollback measured in minutes. The number to track is deployments per week per agent, and the goal is daily.
Lead time for change
Lead time for change is the elapsed time from this needs to change to the change is live for users. For an AI agent, the change passes through six stages, and each stage is a place a team can lose a day or a week.
- Issue identified. An eval failure, a user report, a downstream incident, or an internal review surfaces the gap.
- Hypothesis formed. The team localizes the issue to a prompt section, a tool, a context ingredient, or a model behavior.
- Change drafted. A new prompt, eval, or tool configuration is written and committed.
- Eval suite passes. The standard regression suite runs and clears.
- Reviewer approves. A second pair of eyes - the agent's code review - signs off.
- Change deployed. The change reaches production or a canary cohort.
Where teams get slow is predictable. Step 4 takes hours when the eval suite is not standardized and a human is spot-checking outputs. Step 5 sits in a queue when the reviewer pattern is not named and the change is "just a prompt." Step 6 requires a human to copy and paste into a vendor console when there is no deployment tooling. We have seen teams whose technical change is finished in an afternoon take ten business days to reach users because steps 4 through 6 are unowned.
The fix is the same fix DORA has been recommending for traditional software for fifteen years: tooling and process for the deployment pipeline. Treat prompts as code with version control. Treat evals as tests. Treat deployments as automation. We have written about the architectural pillars - memory, guardrails, structured execution, and real integrations - in what it actually takes to run a team of AIs in production; Anthropic's "Building Effective Agents" guidance (December 2024) describes the same eval-driven loop in agent-specific terms; OpenAI's open-source evals framework gives one canonical implementation pattern. The vocabulary is new; the discipline is not.
Change failure rate
Change failure rate is the percentage of agent changes that cause a regression: an eval score drop, a user-visible incident, or downstream rework. DORA's elite target for traditional software is below fifteen percent; low performers run at thirty to forty-five percent. Most AI agent teams we have audited do not know their number, because they do not log changes and outcomes against each other in a way that lets them compute it.
The failure modes are AI-specific. Naming them is the first half of the work, because what you cannot name you cannot prevent.
Eval coverage gap
The change improves the targeted eval but regresses an untracked behavior. The eval suite was the measurement instrument, and the instrument missed the side effect. In our work shipping multi-agent systems we see this most often when a prompt is tuned for a high-traffic intent and a low-traffic intent silently degrades.
Provider model drift
The change works for the model version pinned today but breaks when the provider releases an update. This is why model version pins count as deployments in their own right - an unpinned upgrade is a deployment that the team did not author, and the failure rate accrues to the team anyway.
Distribution shift
The change works in eval but the production input distribution differs. The classical reference is Quinonero-Candela, Sugiyama, Schwaighofer, and Lawrence, Dataset Shift in Machine Learning (MIT Press, 2009); Koh et al.'s WILDS benchmark (ICML 2021) is the modern applied treatment.
Multi-agent interaction regression
The change is locally correct and globally broken. Two agents that worked well together start producing a worse joint outcome because one of them shifted. This is the failure mode least represented in standard eval frameworks and the one we spend the most time on - the multi-agent topology framing in building your AI team sets the structural context.
Every regression is a failed system, not a failed engineer. The investigation is a blameless root cause, and the operational practice for AI-specific failures gets its own dedicated post later in this series. The measurement here is simply: how many of our changes regressed, and what category of failure did each one fall into?
Mean time to recovery
Mean time to recovery is the elapsed time from user-visible bad agent behavior to rolled-back-or-fixed. Of the four metrics, this is the one we treat as most operationally important for AI agents, because agents fail in production in ways traditional software does not. A misconfigured service throws a 500 and a monitor pages someone. An agent with silent quality drift produces plausible-sounding wrong answers for a week before anyone notices.
We described the technical scaffolding for this in production AI agent reliability. The four recovery patterns the leadership-facing version of that post needs to name are:
- Rollback. Revert to the previous prompt, eval set, tool configuration, or model version pin. This is the single most important capability and the one most teams cannot do in minutes.
- Hotfix. Ship a corrective change that addresses the immediate symptom while a deeper investigation continues.
- Disable. Turn off the agent or the affected capability. The honest move when neither rollback nor hotfix is safe.
- Escalate. Route the affected requests to a human reviewer or to a different agent that is known good.
The prerequisite for all four is that every agent change is versioned, tagged, and rollback-able in minutes. Most teams cannot do this. The operational fix is deployment tooling that treats prompts, evals, tools, and model pins as configuration with version history and one-click rollback - the same tooling discipline that we recommend for traditional services, translated into the AI agent vocabulary. The Site Reliability Engineering literature (Beyer et al., Site Reliability Engineering, Google, 2016, and The Site Reliability Workbook, Google, 2018) gives the broader framing for service-level objectives and error budgets, and the framing transfers cleanly to agents.
The fifth metric: reliability
DORA's 2024 report added reliability as a fifth key metric: the team's ability to meet operational performance goals across availability, latency, and correctness. For AI agents, we reframe reliability as behavior stability under varied input distributions, and we measure four components.
- Cohort accuracy stability. Does the agent perform similarly for power users and new users, for English and non-English inputs, for short and long conversations? The Holistic Evaluation of Language Models work from Stanford's Center for Research on Foundation Models (Liang et al., 2022, ongoing) is the academic motivation for cohort-segmented evaluation.
- Behavior stability under load. Does the agent behave the same way when the system is busy as when it is idle?
- Behavior stability across provider updates. When the underlying model is updated by the provider, does the agent's behavior survive intact? If not, a model version pin is the immediate mitigation, and the long-term fix is an eval suite broad enough to catch drift before it ships.
- Refusal rate stability. The agent does not suddenly start refusing legitimate requests after a prompt change. Refusal regressions are a category of change failure that standard accuracy evals miss entirely.
The operational practice is a reliability eval suite that runs daily, segmented by cohort, with alerts on drift. Hendrycks and Dietterich's robustness work (ICLR 2019) gives the underlying vocabulary; the implementation we recommend is the simplest one your team can run every day without exception.
How to instrument the four
The minimum viable instrumentation is four artifacts and one cadence. We have run this exact setup on agents we ship, and we have watched it move the four metrics within a quarter just from the visibility it creates. The principle here is Measure Before Disrupting: you cannot improve a delivery pipeline you have not measured.
Deployment log
Every prompt, eval, tool, and model change is logged with timestamp, author, agent identifier, and change type. Without this you cannot compute deployment frequency or lead time. With it, both metrics fall out of a query.
Eval pipeline
Every change runs against the standard eval suite before deployment. The pipeline gates the deployment log. A change that does not run evals is a deployment with an unknown change failure rate, which is to say a deployment you should not ship.
Incident log
Every user-visible bad behavior is logged with severity, agent identifier, recovery action, and time-to-recovery. Mean time to recovery comes from this log; change failure rate comes from cross-referencing it with the deployment log.
Weekly review
Leadership looks at all four numbers per agent per week. One page per agent. Four numbers each. Trends called out, surprises explained, the next capability investment named. The review is the forcing function the rest of the discipline answers to.
The cadence is weekly review with the agent owner, monthly review with engineering leadership, quarterly retrospective with the broader organization. The quarterly retrospective is where capability investments - better eval tooling, better deployment tooling, better observability - get prioritized against the metric they are intended to move. This is also where the rule discipline we described in obey the rules or die becomes a measurable input to change failure rate: a pre-deployment rule check is the single highest-leverage intervention we have found for the metric.
Existing production tooling - Promptfoo, Braintrust, LangSmith, Lakera, and others in the eval and observability space - implements pieces of this. We are deliberately not endorsing a specific vendor. The landscape moves quickly enough that any endorsement here will be wrong by the time you read it. The framework is the durable thing.
How to start tomorrow
The framework is too big to adopt in one week. It is small enough to start practicing in one week. Pick one agent and run the following four steps over the next month. The rest follows once the visibility exists.
Pick one agent and start logging deployments
Add a basic eval suite if you do not have one
Track failures and recoveries for a month
Share the numbers with the team and pick one capability to invest in
Two later posts in this series build on this foundation. One is the lifecycle of an AI agent on the team - onboarding, ownership, retirement - which is the agent equivalent of the people-operations work we run on human teammates. The other is what to do when an agent underperforms, which is the agent equivalent of the lead-coach-or-manage-out doctrine from Building Teams That Build Systems. Both assume the four metrics are in place. Without them, the conversations are guesses.
Why this is the operational floor
DORA gave traditional software teams a vocabulary for delivery performance. The teams that adopted that vocabulary compounded on operational quality through the entire 2010s and are now the teams everyone else tries to learn from. AI agent teams need the same vocabulary now. The translation is small. The discipline is large. The compounding is the same.
We have argued elsewhere - in measuring velocity wrong - that the wrong metrics waste a year of a team's attention. The four DORA metrics, translated for AI agents, are the right metrics. Adopt them now and the year a team would have lost on vanity dashboards is a year spent compounding on the capability that actually ships.
Instrument your agent team
If you are building AI agent systems and want to apply the four DORA metrics to your team, or if you are interested in the operational practice behind these posts, we should talk.